After programming for a while you start getting a feel for the design of a program. You start to know when data should be encapsulated, when a new class is needed, how the classes should interact, etc…. A lot can be leaned from OOP principles taught by nearly every programming teacher. I personally thou had doubts about some concepts in OOP which are prevalent in programming languages like Java or C#. I really dislike the lack of control over memory and the use of heap memory for every object. The deeper I got into programming the more I tried to make my code fast by employing templates and maximising the use of compile time constants. While using the Onion Design together with Mixins I gave myself the illusion of fast and efficient code. Oh how wrong I was…
The Cache
The cache of a CPU is utilized as a buffer area which gets filled up with data after each read from memory. A hierarchy of levels is present is most CPU designs which are labeled with L1, L2 or L3. The size of these caches are dependant on the model used. For example here are my CPU caches.
CPU Caches:
L1 Data 32 KiB (x4)
L1 Instruction 32 KiB (x4)
L2 Unified 256 KiB (x4)
L3 Unified 6144 KiB (x1)
We are interested in the L1 Data cache.
L1 Data Cache
Loading data from memory is slow. A typical read from memory could involve somewhere around 400 cycles. For reference a successful read from the L1 Data cache is about 4 cycles. Here is a nice chart putting the values into context.
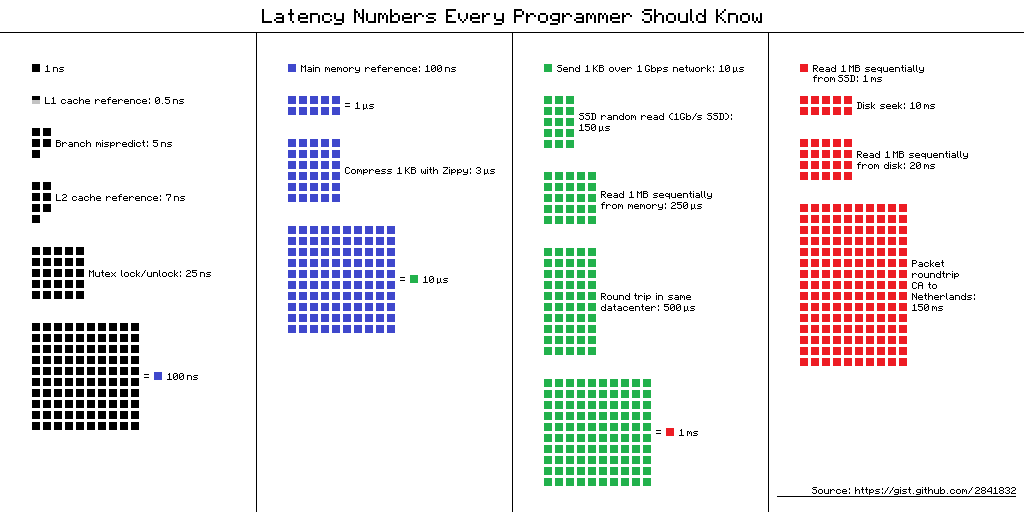
The CPU makes use of the L1 Data cache to read batches of memory. For example if you request a int variable the CPU looks inside the cache for it and if not found gets it from memory together with 64 bytes of additional data and stores them into the cache. This will allow the CPU to simply access the cache for additional values.
Cache Miss
When in fact the CPU doesn’t find the requested value inside the cache, a so called Cache Miss happens. A Cache Miss describes a failed attempt to read a certain value from the cache, which results in a read operation from main memory. Cache Miss is often used when criticising inefficient code.
In Practice
Why do we care about this? Isn’t this so low level that we have little control over it? Well, not entirely. When you compile a program the compiler tries to optimize your program in such a way that it maximises the usage of the cache. Yet the compiler doesn’t change to program. Inefficient algorithms will stay inefficient, just well optimized. By keeping the cache in mind we can improve our programs to perform tasks at lightning speeds!
Typical Example
Lets say we have a matrix and we want to fill it up with each cell having the sum of its row and column. This results in the simple program as follows.
constexpr unsigned h = 1000, w = 1000;
unsigned x[h][w];
for (unsigned ii = 0; ii < w; ++ii)
for (unsigned i = 0; i < h; ++i)
x[i][ii] = i + ii;This program is deeply flawed. Looking at the performance we get this.
----------------------------
Benchmark Time
----------------------------
BM_ClassicBad 4837 ns
For reference there is a algorithm which has a better performance.
BM_ClassicGood 932 ns
And the code simply looks like this.
constexpr unsigned h = 1000, w = 1000;
unsigned x[h][w];
for (unsigned i = 0; i < w; ++i)
for (unsigned ii = 0; ii < h; ++ii)
x[i][ii] = i + ii;What has changed? Instead of using the outer array to access the elements we first go through all inner arrays. Lets visualize this.
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
|0,0|0,1|0,2|...|1,0|1,1|1,2|...|2,0|2,1|2,2|...|3,0|3,1|3,2|...|
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
This is a multidimensional array. Multidimensional arrays are always appended behind each other. When we look at how our first implementation accesses the array…
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
|0,0|0,1|0,2|...|1,0|1,1|1,2|...|2,0|2,1|2,2|...|3,0|3,1|3,2|...|
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
↑ ↑ ↑ ↑
1 2 3 4
It jumps through the array to access the elements. The cache isn’t designed for this and frequently a cache miss happens. A better version of the algorithm would be if we actually use these values which our cache holds.
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
|0,0|0,1|0,2|...|1,0|1,1|1,2|...|2,0|2,1|2,2|...|3,0|3,1|3,2|...|
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑
1 2 3 4 5 6 7 8 9 10 11 12
Our second algorithm actually uses the values loaded into the cache. As such the algorithm becomes ~5x faster.
A Different Example
The problem is mostly present in code that processes arrays. Here is another example which could fit more into your daily programs.
struct Vec
{
int j, k, l, u, p, v, b, n, m, y, x;
};
constexpr unsigned n = 10000;
Vec v1[n];
for (size_t i = 0; i < n; ++i) v1[i].j = v1[i].k + v1[i].l;And here are its benchmark results.
------------------------
Benchmark Time
------------------------
BM_Class 10027 ns
We can predict what is causing the slow down here. Massive amounts of useless data is polluting our L1 Data cache. A better algorithm would be just using arrays of integers. Like so…
constexpr unsigned n = 10000;
int x[n];
int y[n];
int res[n];
for (size_t i = 0; i < n; ++i) res[i] = x[i] + y[i];Which as we predicted it gives us a much better result.
BM_Data 1759 ns
The code is ~6x faster than the previous one.
If we decrease the amount of useless variables which are additionally loaded into the cache we should get a increase in speed.
struct Vec
{
int j, k, l;
};Here is its benchmark.
BM_Class 5040 ns
The execution speed has definitely improved but it still doesn’t rival the speed of BM_Data. Notice we are loading the data at j. We don’t need it, since we are only writing to it. We don’t care what value was there before overwriting it.
struct Vec
{
int k, l;
};
constexpr unsigned n = 10000;
Vec v1[n];
int res[n];
for (size_t i = 0; i < n; ++i) res[i] = v1[i].k + v1[i].l;This improves the speed.
BM_Class 4454 ns
Yet it still doesn’t match the speed when using single arrays. The reason for this is shown in the assembly code. Compiling with clang++ -O3 gives us the following result.
movdqa xmm0, xmmword ptr [rsp + 4*rax + 39952]
movdqa xmm1, xmmword ptr [rsp + 4*rax + 39968]
movdqa xmm2, xmmword ptr [rsp + 4*rax + 39984]
movdqa xmm3, xmmword ptr [rsp + 4*rax + 40000]
paddd xmm0, xmmword ptr [rsp + 4*rax + 79952]
paddd xmm1, xmmword ptr [rsp + 4*rax + 79968]
movdqa xmmword ptr [rsp + 4*rax - 48], xmm0
movdqa xmmword ptr [rsp + 4*rax - 32], xmm1
paddd xmm2, xmmword ptr [rsp + 4*rax + 79984]
paddd xmm3, xmmword ptr [rsp + 4*rax + 80000]
movdqa xmmword ptr [rsp + 4*rax - 16], xmm2
movdqa xmmword ptr [rsp + 4*rax], xmm3
add rax, 16
cmp rax, 10012
jne .LBB2_3These are SIMD operations. I won’t explain entirely what SIMD is, since that’s out of scope of this post but in short the compiler tries to make the CPU perform multiple additions at once. Which results in a definite speed up.
Conclusion
By having the data in mind one can make code significantly faster. When planning a project you should have the organization of data in mind. You could possibly even plan the whole program having only the storage and tranformations of data in mind. After all the task of a program is nothing more but reading, transforming and writing data.
Try to only load data you really need for operations, especially for code which is repeated often. I’m not saying not to use classes at all. Classes are fine as long as everything within the class is used for the operation the class is needed for.